Persisted Queries
Usa le query GraphQL per creare endpoint predefiniti come in REST, ottenendo i vantaggi di entrambe le API.
Descrizione
Con REST, crei più endpoint, ognuno dei quali restituisce un insieme predefinito di dati.
| Vantaggi | Svantaggi |
|---|---|
| ✅ È semplice | ❌ È tedioso creare tutti gli endpoint |
✅ Accessibile via GET o POST | ❌ Un progetto può incontrare colli di bottiglia in attesa che gli endpoint siano pronti |
| ✅ Può essere messo in cache sul server o sulla CDN | ❌ Produrre la documentazione è obbligatorio |
| ✅ È sicuro: vengono esposti solo i dati previsti | ❌ Può essere lento (soprattutto per le app mobili), poiché l'applicazione potrebbe aver bisogno di più richieste per recuperare tutti i dati |
Con GraphQL, fornisci qualsiasi query a un singolo endpoint, che restituisce esattamente i dati richiesti.
| Vantaggi | Svantaggi |
|---|---|
| ✅ Nessun sotto/sovra-recupero di dati | ❌ Accessibile solo via POST |
| ✅ Può essere veloce, poiché tutti i dati vengono recuperati in una singola richiesta | ❌ Non può essere messo in cache sul server o sulla CDN, rendendolo più lento e più costoso |
| ✅ Permette un'iterazione rapida del progetto | ❌ Può richiedere di reinventare la ruota, come per l'upload di file o la messa in cache |
| ✅ Può essere auto-documentato | ❌ Deve affrontare complessità aggiuntive, come il problema N+1 |
| ✅ Fornisce un editor per la query (GraphiQL) che semplifica il compito |
Le persisted queries combinano questi 2 approcci:
- Usano GraphQL per creare e risolvere le query
- Ma invece di esporre un singolo endpoint, espongono ogni query predefinita sotto il proprio endpoint
Così, otteniamo più endpoint con dati predefiniti, come in REST, ma creati con GraphQL, ottenendo i vantaggi di ciascuno ed evitando i loro svantaggi:
| Vantaggi | Svantaggi |
|---|---|
✅ Accessibile via GET o POST | |
| ✅ Può essere messo in cache sul server o sulla CDN | |
| ✅ È sicuro: vengono esposti solo i dati previsti | |
| ✅ Nessun sotto/sovra-recupero di dati | |
| ✅ Può essere veloce, poiché tutti i dati vengono recuperati in una singola richiesta | POST |
| ✅ Permette un'iterazione rapida del progetto | |
| ✅ Può essere auto-documentato | |
| ✅ Fornisce un editor per la query (GraphiQL) che semplifica il compito |

Esecuzione della Persisted Query
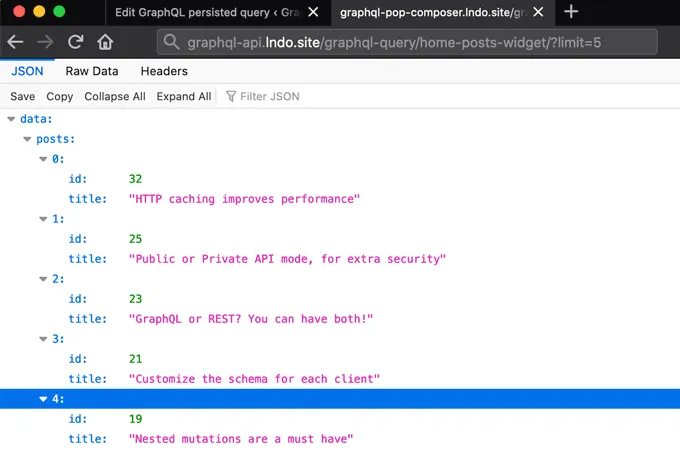
Una volta pubblicata la persisted query, possiamo eseguirla tramite il suo permalink.
La persisted query può essere eseguita direttamente nel browser, poiché è accessibile via GET, e otterremo i dati richiesti in formato JSON:
Creazione di una Persisted Query
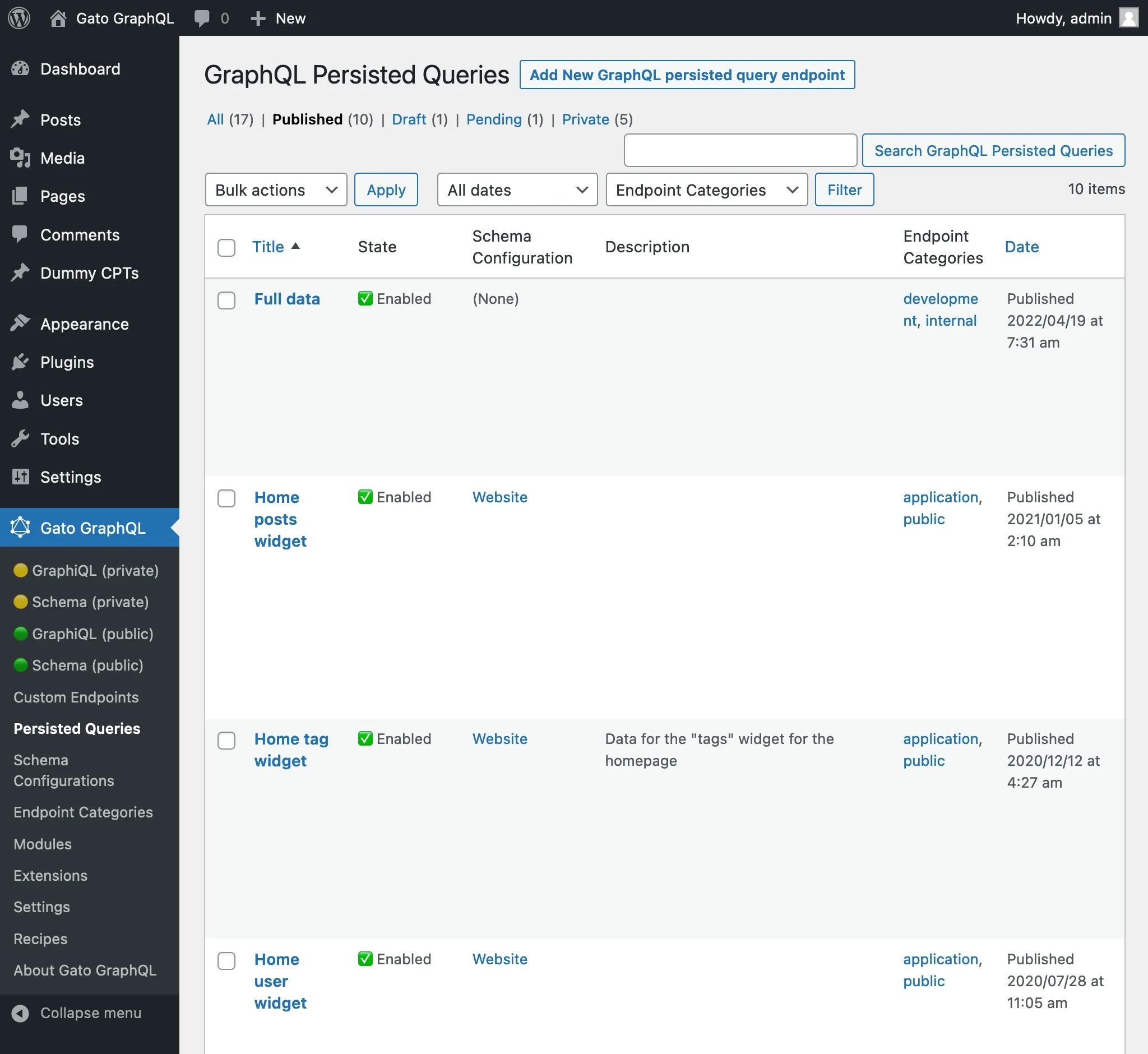
Cliccando sul link Persisted Queries nel menu, viene visualizzato l'elenco di tutte le persisted queries create:
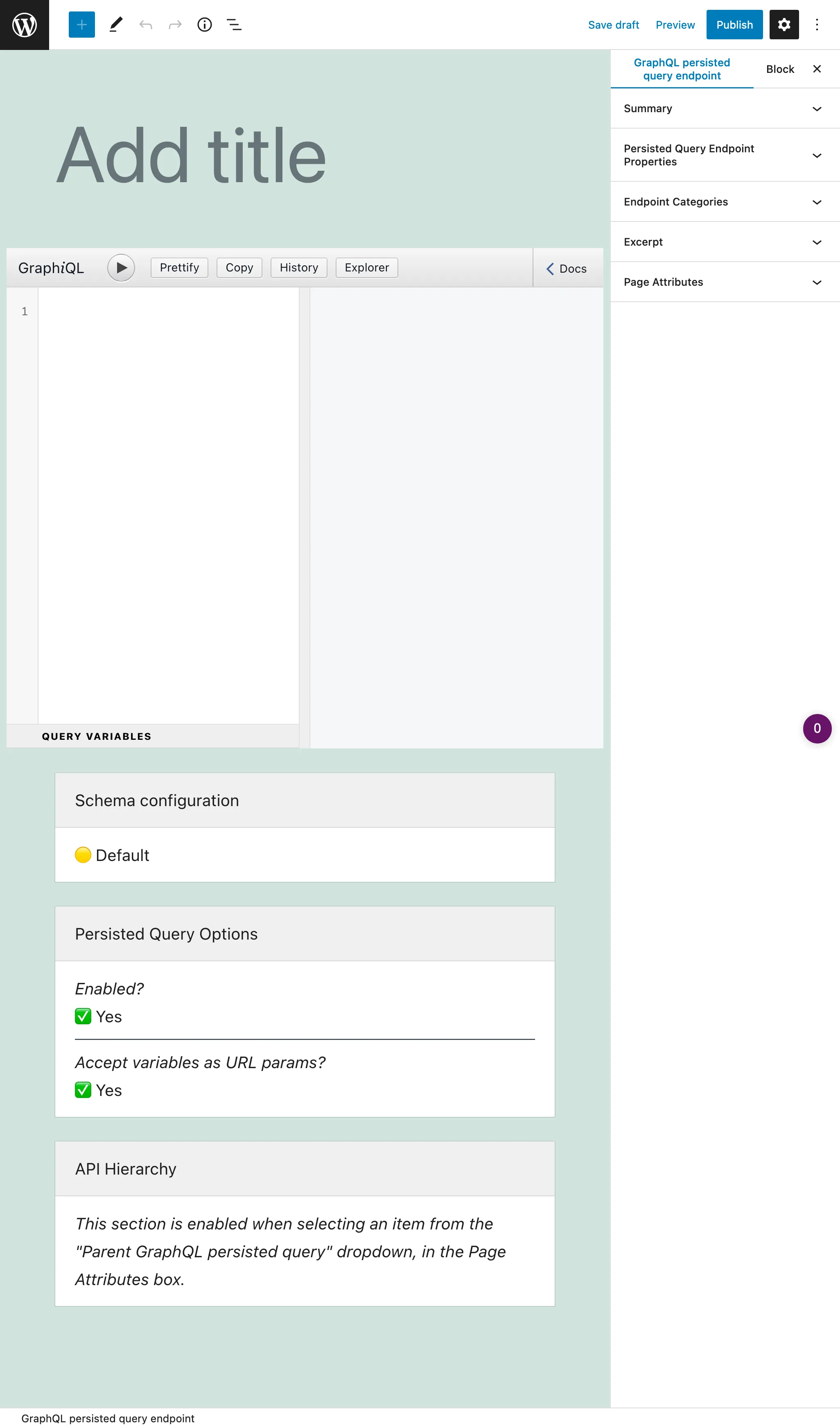
Una persisted query è un custom post type (CPT). Per creare una nuova persisted query, clicca sul pulsante "Aggiungi una nuova persisted query GraphQL", che aprirà l'editor di WordPress:
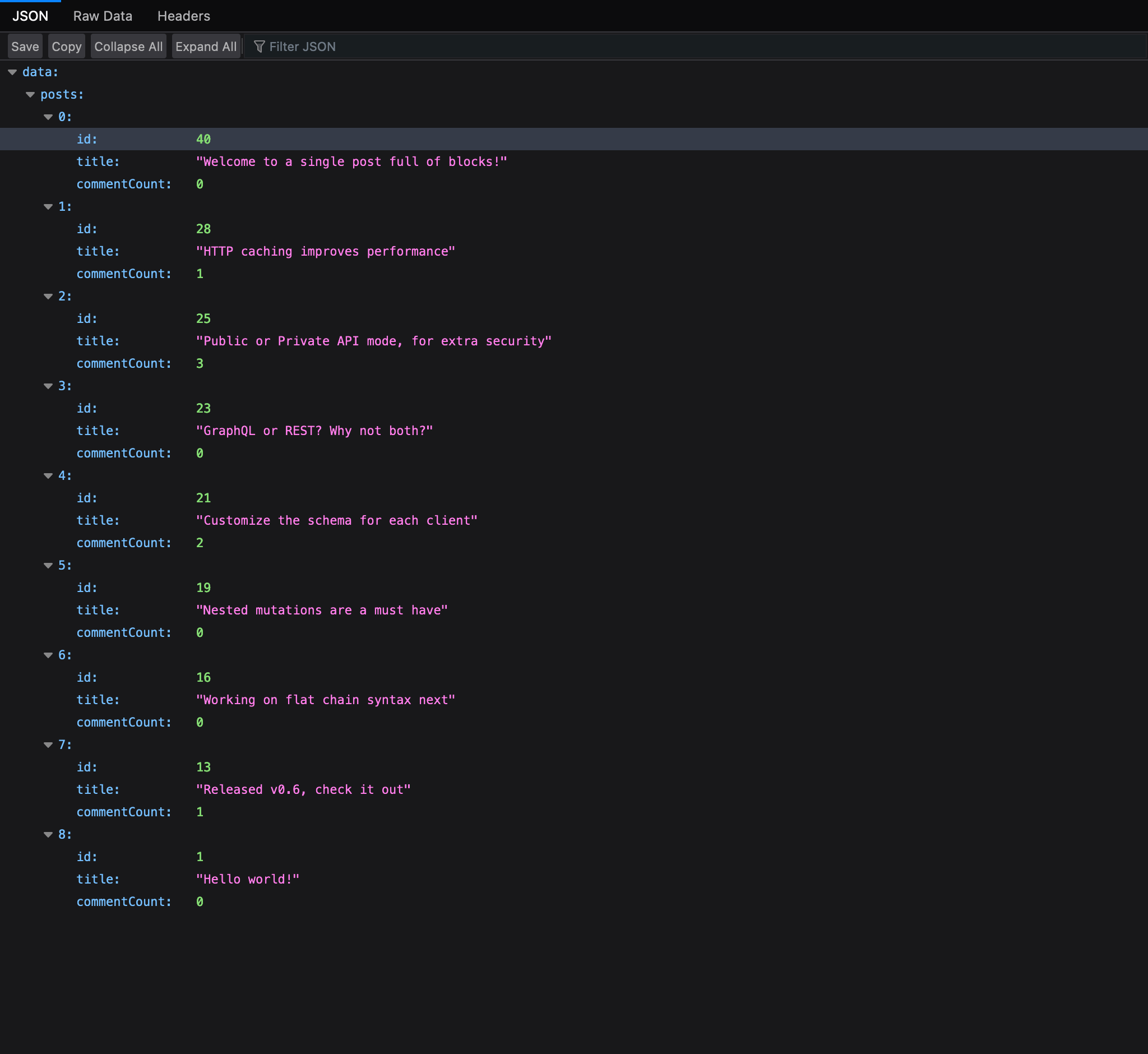
L'input principale è il client GraphiQL, che è fornito con l'Explorer per impostazione predefinita. Cliccare sui campi nel pannello laterale sinistro li aggiunge alla query, e cliccare sul pulsante "Run" esegue la query:

Quando la query è pronta, pubblicala, e il suo permalink diventa il suo endpoint. Il link all'endpoint (e alla sorgente) è mostrato nel pannello laterale "Pagina principale dell'Endpoint di Persisted Query":
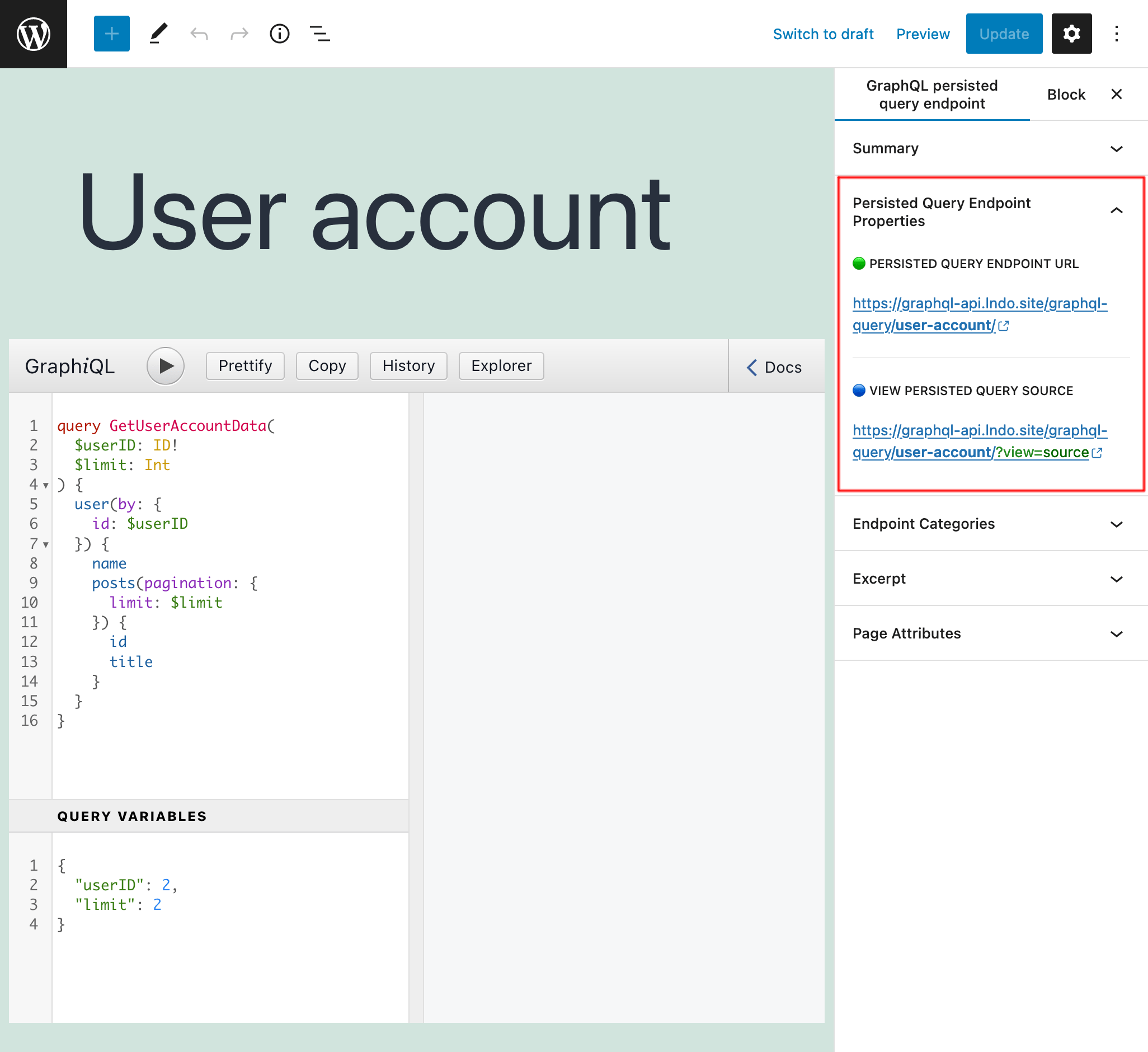
Aggiungendo ?view=source al permalink, verranno mostrate la persisted query e la sua configurazione (a condizione che l'utente sia connesso e che il suo ruolo abbia accesso):

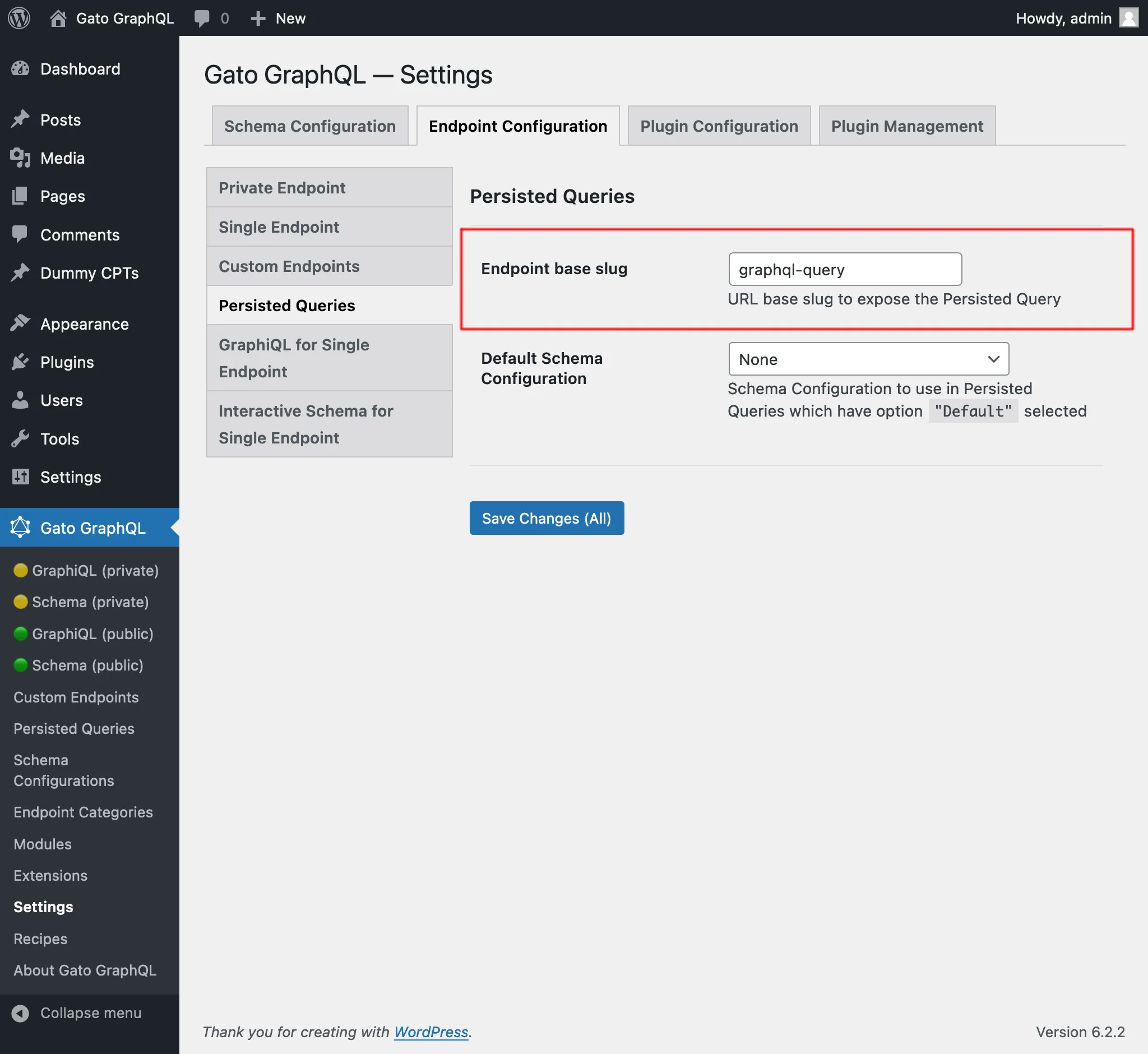
Per impostazione predefinita, l'endpoint della persisted query ha il percorso /graphql-query/, e questo valore è configurabile tramite le Impostazioni:
Configurazione dello schema
La definizione di quali elementi contiene lo schema, e di quale accesso vi avranno gli utenti, è definita nella configurazione dello schema.
Quindi dobbiamo creare una configurazione dello schema, e poi selezionarla dal menu a tendina:

Organizzazione delle Persisted Queries per categoria
Nel pannello laterale "Categorie di endpoint" possiamo aggiungere categorie per aiutare a gestire la Persisted Query:
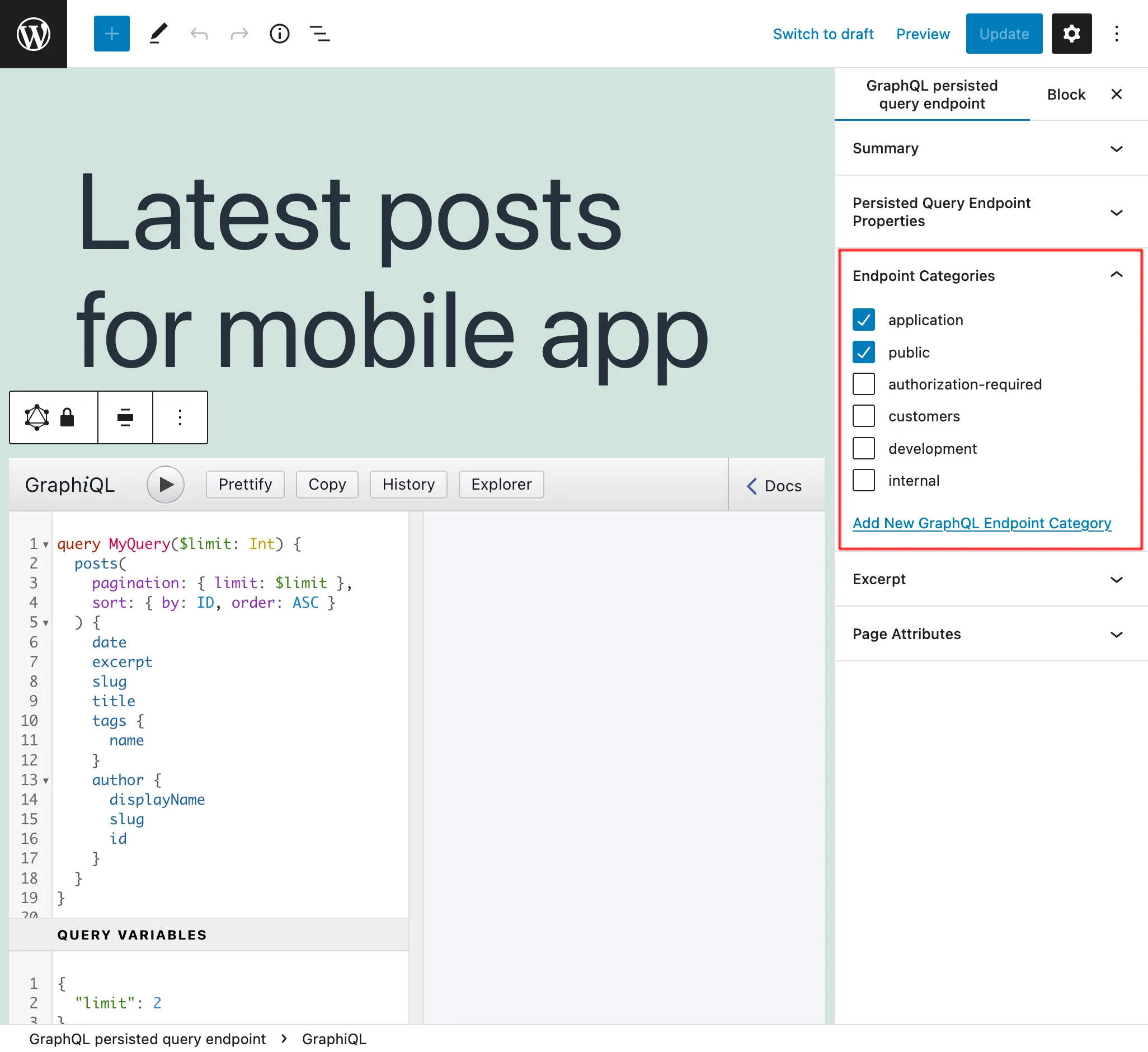
Ad esempio, possiamo creare categorie per gestire gli endpoint per cliente, applicazione, o qualsiasi altra informazione necessaria:

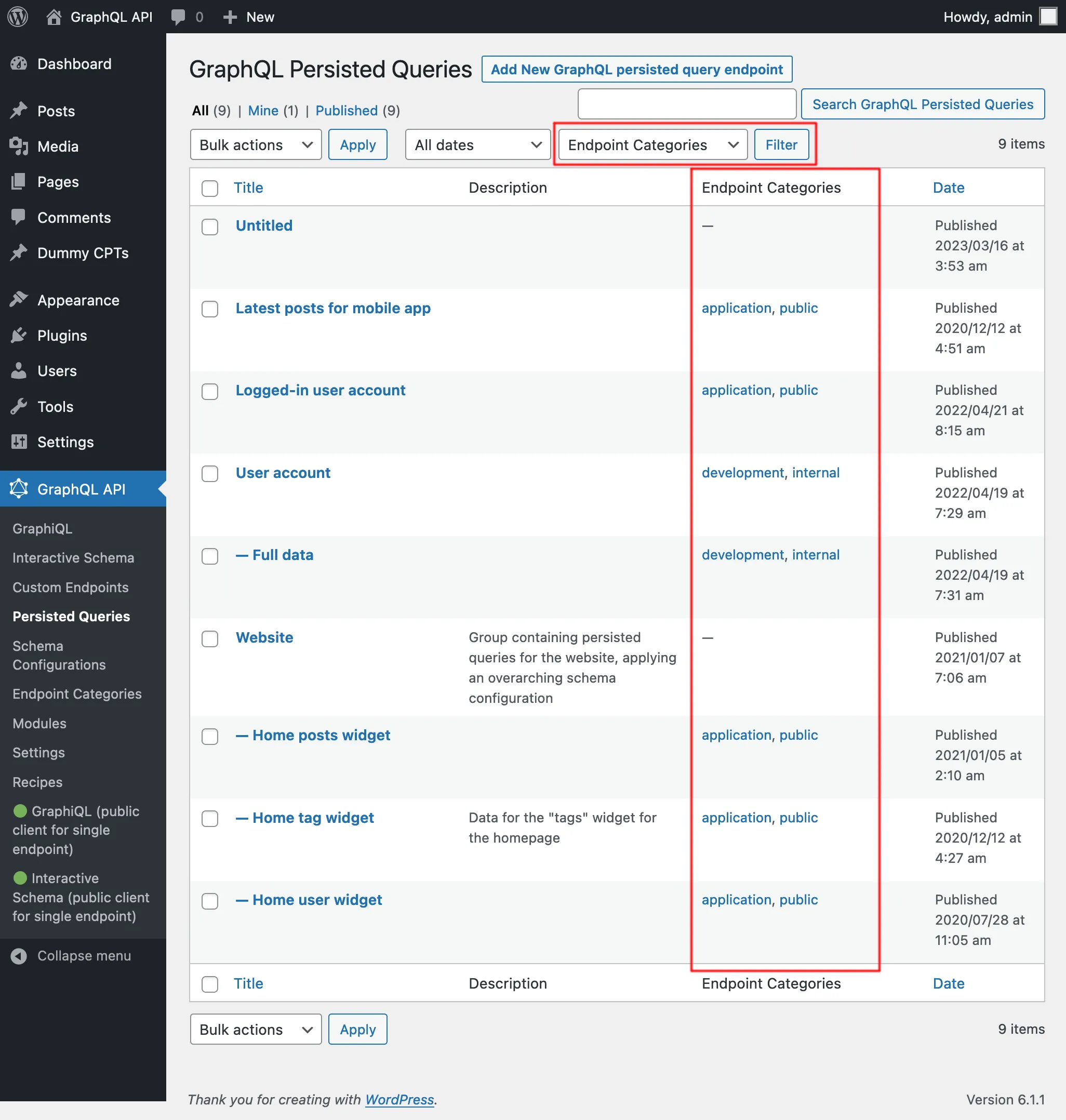
Nell'elenco delle Persisted Queries, possiamo visualizzare le loro categorie e, cliccando su qualsiasi link di categoria, o usando il filtro in alto, verranno mostrate solo le voci di quella categoria:
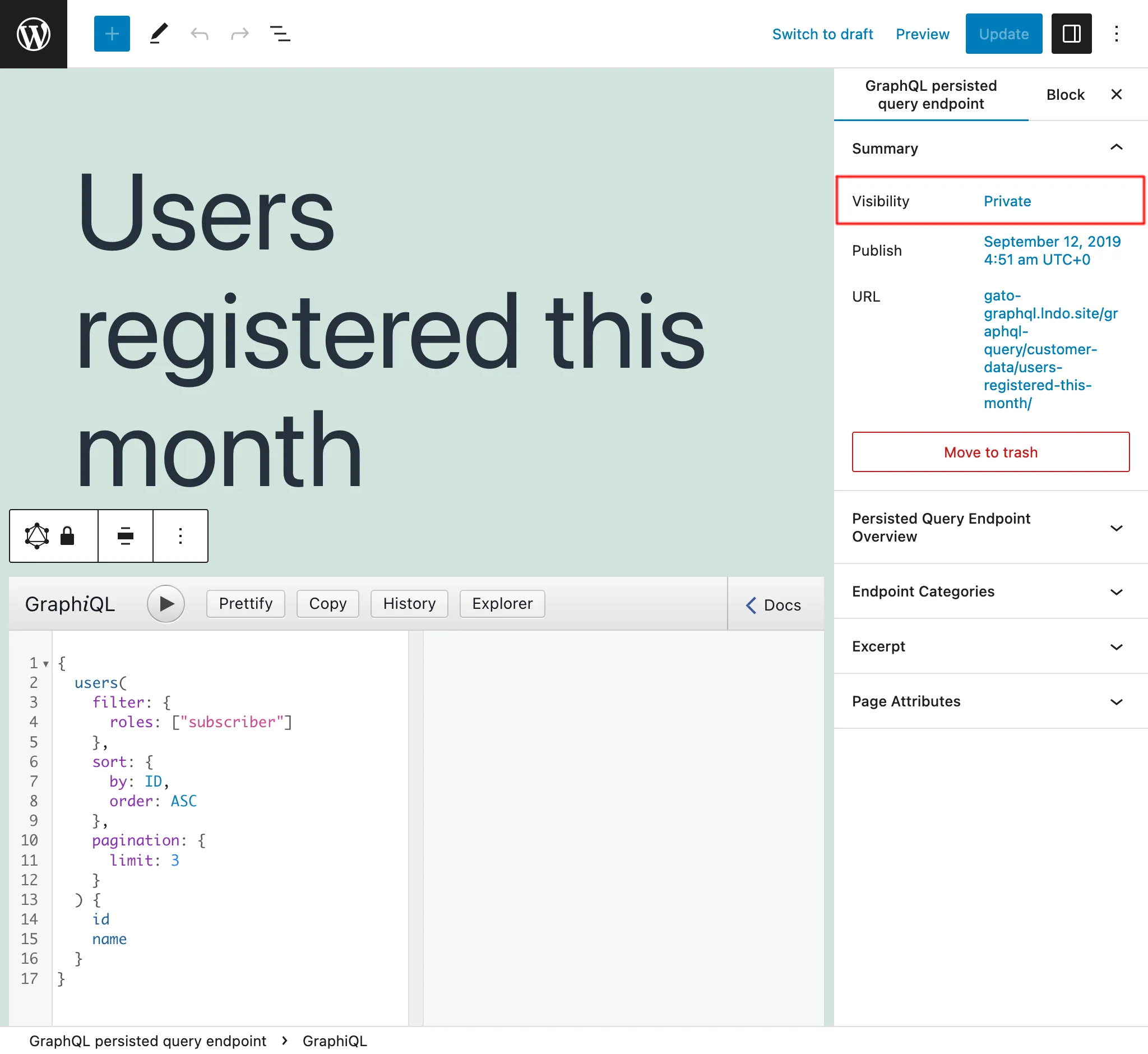
Persisted queries private
Impostando lo stato della Persisted Query su private, l'endpoint può essere accessibile solo dall'utente amministratore. Questo evita che i nostri dati vengano condivisi involontariamente con utenti che non dovrebbero avervi accesso.
Ad esempio, possiamo creare Persisted Queries private per aiutare a gestire l'applicazione, come il recupero di dati per creare report con le nostre metriche.
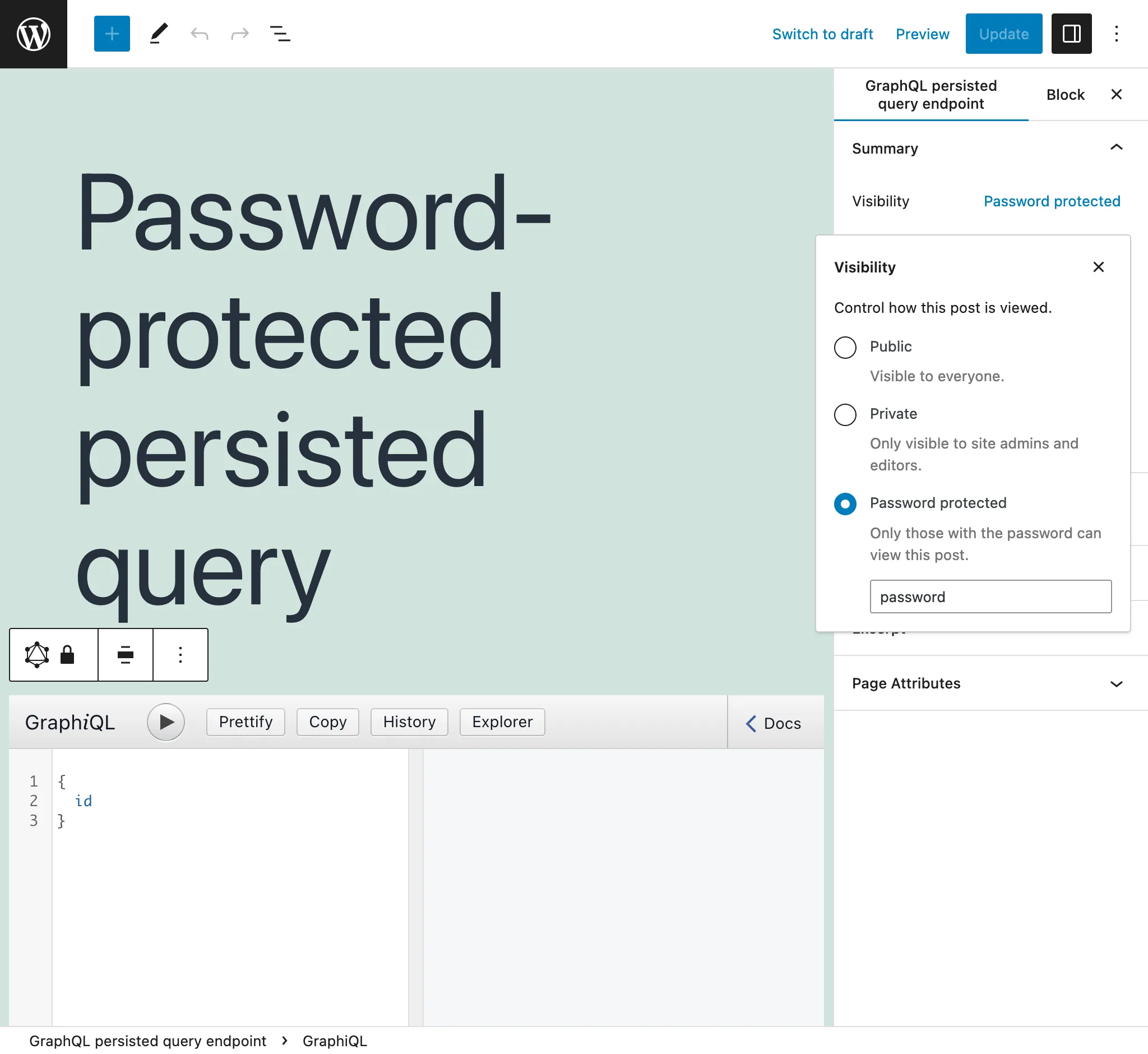
Persisted queries protette da password
Se creiamo una Persisted Query per un cliente specifico, possiamo assegnarle una password, per fornire un livello di sicurezza aggiuntivo e fare in modo che solo quel cliente acceda all'endpoint.
Al primo accesso a una persisted query protetta da password, ci troviamo davanti a una schermata che richiede la password:
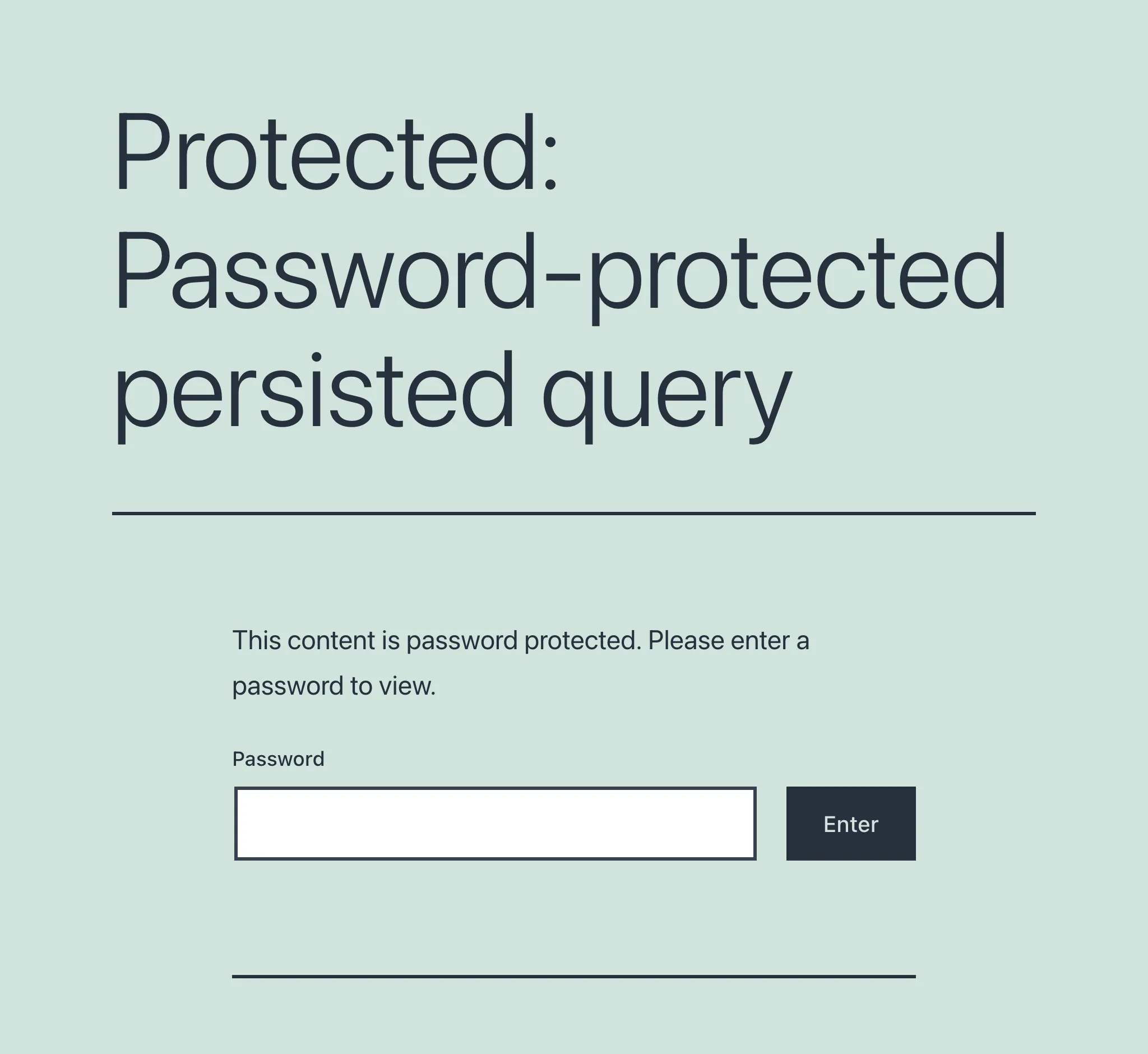
Una volta fornita e validata la password, solo allora l'utente accederà all'endpoint previsto.
Rendere la persisted query dinamica tramite parametri URL
Il valore di ciascuna variabile può essere impostato tramite un parametro URL (con il nome della variabile) durante l'esecuzione della persisted query. Se l'opzione "I parametri URL sovrascrivono le variabili?" è abilitata, allora il parametro URL avrà la priorità. Altrimenti, avrà la priorità il valore definito nel dizionario delle variabili (se presente).
Ad esempio, in questa query, il numero di risultati è controllato tramite la variabile $limit, con un valore predefinito di 3:
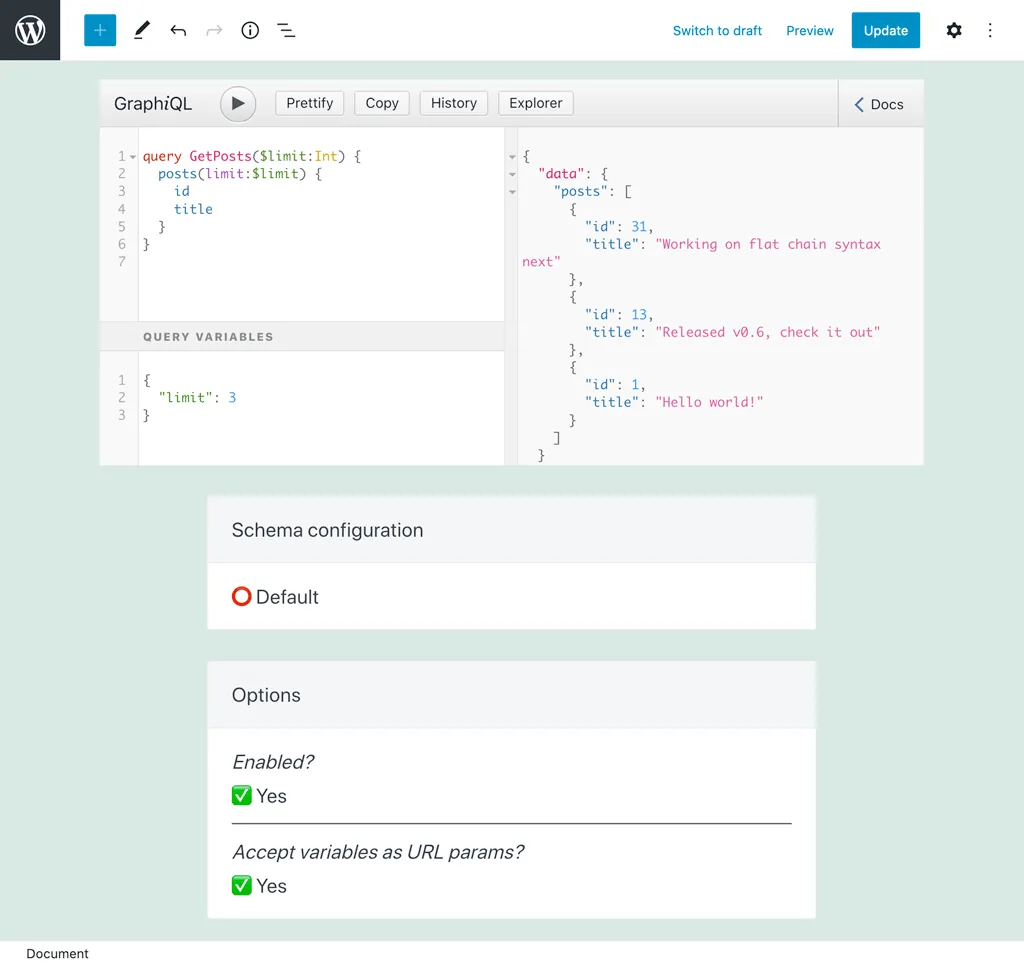
Durante l'esecuzione di questa persisted query, passare ?limit=5 eseguirà la query restituendo invece 5 risultati: