
Motore di caricamento dei dati
Gato GraphQL utilizza componenti lato server per rappresentare il modello di dati (non grafi né alberi). Vediamo come esegue il processo di caricamento dei dati per risolvere la query GraphQL.
Per elaborare i dati, dobbiamo appiattire i componenti in tipi (<FeaturedDirector> => Director, <Film> => Film, <Actor> => Actor), ordinarli in base alla loro comparsa nella gerarchia dei componenti (Director, poi Film, poi Actor) e trattarli per "iterazioni", recuperando i dati degli oggetti per ogni tipo nella sua propria iterazione, così:

Il motore di caricamento dei dati del server deve implementare il seguente (pseudo-)algoritmo per caricare i dati:
Preparazione:
- Preparare una coda vuota per memorizzare l'elenco degli ID degli oggetti da recuperare dal database, organizzati per tipo (ogni voce sarà:
[type => elenco di ID]) - Recuperare l'ID dell'oggetto regista in evidenza e collocarlo nella coda sotto il tipo
Director
Ciclo fino a quando non ci sono più voci nella coda:
- Ottenere la prima voce dalla coda: il tipo e l'elenco degli ID (es.:
Directore[2]), quindi rimuovere questa voce dalla coda - Utilizzando l'oggetto
TypeDataLoaderdel tipo, eseguire una singola query contro il database per recuperare tutti gli oggetti di quel tipo con quegli ID - Se il tipo possiede campi relazionali (es.: il tipo
Directorpossiede il campo relazionalefilmsdi tipoFilm), allora raccogliere tutti gli ID di questi campi da tutti gli oggetti recuperati nell'iterazione corrente (es.: tutti gli ID del campofilmsdi tutti gli oggetti di tipoDirector), e collocare questi ID nella coda sotto il tipo corrispondente (es.: gli ID[3, 8]sotto il tipoFilm).
Al termine delle iterazioni, avremo caricato tutti i dati degli oggetti per tutti i tipi, così:
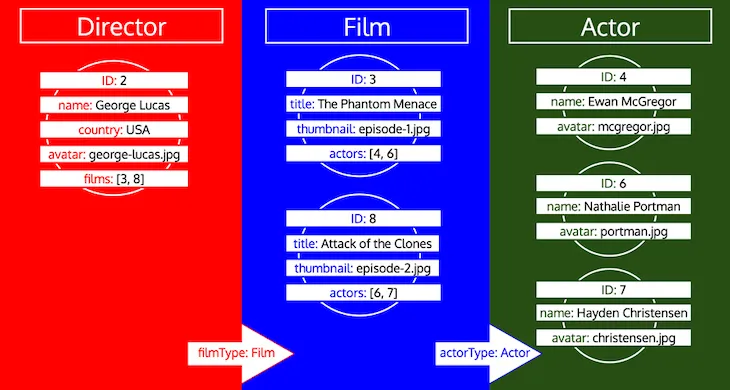
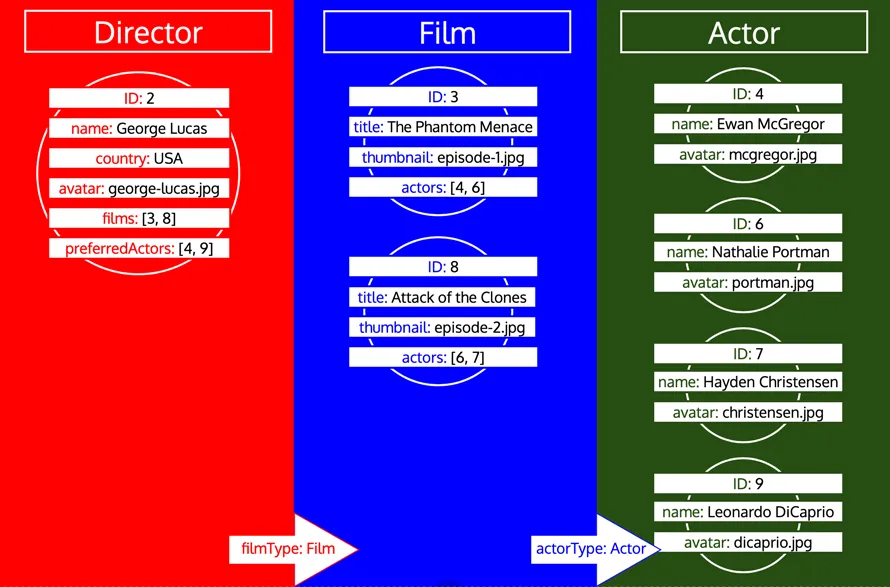
Notate come tutti gli ID di un tipo vengono raccolti finché quel tipo non viene elaborato nella coda. Se, ad esempio, aggiungiamo un campo relazionale preferredActors al tipo Director, questi ID verrebbero aggiunti alla coda sotto il tipo Actor, e verrebbero elaborati insieme agli ID del campo actors del tipo Film:
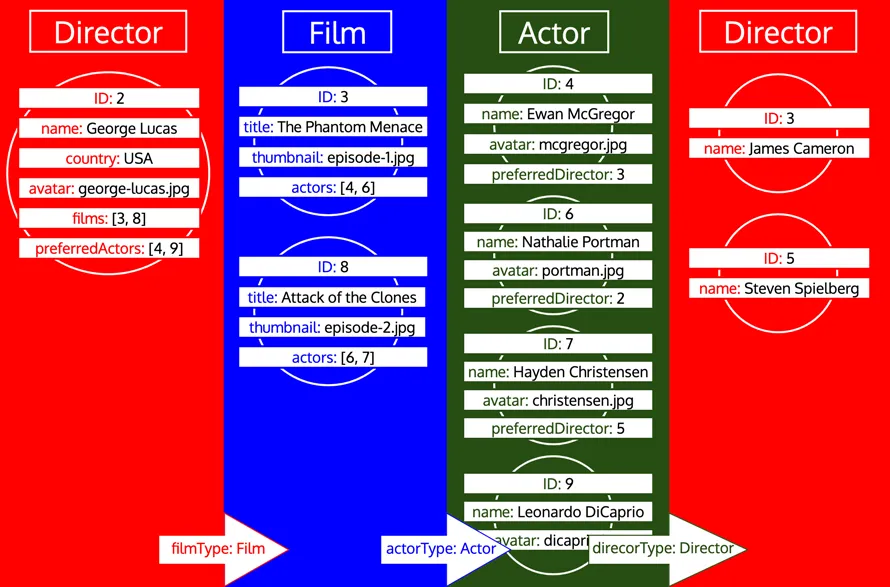
Tuttavia, se un tipo è già stato elaborato e in seguito è necessario caricare altri dati di quel tipo, si tratta di una nuova iterazione su quel tipo. Ad esempio, aggiungere un campo relazionale preferredDirector al tipo Author farà sì che il tipo Director venga aggiunto di nuovo alla coda:
Ora che abbiamo recuperato tutti i dati degli oggetti, dobbiamo dare loro la forma della risposta attesa, rispecchiando la query GraphQL. Tuttavia, come si può notare, i dati non hanno la struttura ad albero richiesta. I campi relazionali contengono invece gli ID dell'oggetto annidato, emulando il modo in cui i dati sono rappresentati in un database relazionale. Pertanto, seguendo questo confronto, i dati recuperati per ogni tipo possono essere rappresentati sotto forma di tabella, così:
Tabella per il tipo Director:
| ID | name | country | avatar | films |
|---|---|---|---|---|
| 2 | George Lucas | USA | george-lucas.jpg | [3, 8] |
Tabella per il tipo Film:
| ID | title | thumbnail | actors |
|---|---|---|---|
| 3 | The Phantom Menace | episode-1.jpg | [4, 6] |
| 8 | Attack of the Clones | episode-2.jpg | [6, 7] |
Tabella per il tipo Actor:
| ID | name | avatar |
|---|---|---|
| 4 | Ewan McGregor | mcgregor.jpg |
| 6 | Nathalie Portman | portman.jpg |
| 7 | Hayden Christensen | christensen.jpg |
Avendo tutti i dati organizzati in tabelle, e sapendo come ogni tipo è correlato agli altri (cioè Director fa riferimento a Film tramite il campo films, Film fa riferimento a Actor tramite il campo actors), il server GraphQL può facilmente convertire i dati nella struttura ad albero attesa:
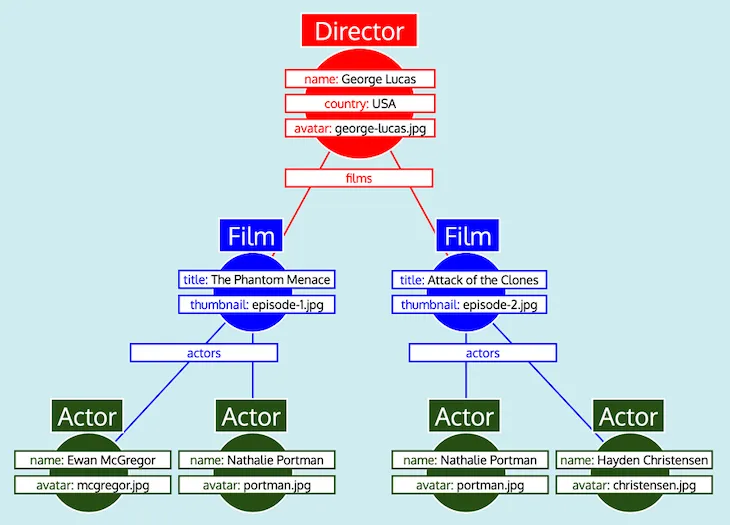
Infine, il server GraphQL emette l'albero, che ha la forma della risposta attesa:
{
data: {
featuredDirector: {
name: "George Lucas",
country: "USA",
avatar: "george-lucas.jpg",
films: [
{
title: "Star Wars: Episode I",
thumbnail: "episode-1.jpg",
actors: [
{
name: "Ewan McGregor",
avatar: "mcgregor.jpg",
},
{
name: "Natalie Portman",
avatar: "portman.jpg",
}
]
},
{
title: "Star Wars: Episode II",
thumbnail: "episode-2.jpg",
actors: [
{
name: "Natalie Portman",
avatar: "portman.jpg",
},
{
name: "Hayden Christensen",
avatar: "christensen.jpg",
}
]
}
]
}
}
}Analisi della complessità temporale della soluzione
Analizziamo la notazione O grande dell'algoritmo di caricamento dei dati per capire come il numero di query eseguite contro il database cresce man mano che il numero di input aumenta, così da assicurarci che questa soluzione sia performante.
Il motore di caricamento dei dati carica i dati in iterazioni corrispondenti a ciascun tipo. Nel momento in cui avvia un'iterazione, dispone già dell'elenco di tutti gli ID di tutti gli oggetti da recuperare, e può quindi eseguire una singola query per recuperare tutti i dati degli oggetti corrispondenti. Ne consegue che il numero di query verso il database crescerà in modo lineare con il numero di tipi coinvolti nella query. In altre parole, la complessità temporale è O(n), dove n è il numero di tipi nella query (tuttavia, se un tipo viene iterato più di una volta, deve essere conteggiato più di una volta in n).
Questa soluzione è molto performante, decisamente migliore della complessità esponenziale attesa nel trattamento dei grafi, o della complessità logaritmica attesa nel trattamento degli alberi.
Codice PHP implementato
Il processo di caricamento dei dati si svolge nella funzione getComponentData della classe Engine del pacchetto Component Model.