
Pipeline di direttive
Le direttive vengono inserite in un pipeline ed eseguite in ordine. Il loro design iniziale è semplice, come questo:

In questa architettura:
- L'input del pipeline è il valore del campo fornito dal resolver del campo
- Ogni direttiva esegue la propria logica e passa il risultato alla direttiva successiva nel pipeline
- L'output del pipeline sarà il valore del campo risolto, dopo essere stato elaborato da tutte le direttive
Questa architettura, però, non sfrutta al meglio GraphQL. Di seguito è riportata la descrizione di tutte le fasi del pipeline di direttive effettivo, fino ad arrivare al design realmente implementato in Gato GraphQL.
Le direttive come blocchi costitutivi della risoluzione della query
Inizialmente potremmo pensare di far risolvere il campo al server GraphQL tramite qualche meccanismo, per poi passare questo valore come input al pipeline di direttive.
Tuttavia, è molto più semplice avere un unico meccanismo per gestire tutto: invocare i resolver dei campi (sia per validare i campi sia per risolverli) può già essere fatto tramite il pipeline di direttive. In questo caso, il pipeline di direttive è l'unico meccanismo utilizzato per risolvere la query.
Per questo motivo, il server Gato GraphQL è dotato di due direttive speciali:
@validatechiama il resolver del campo per validare che il campo possa essere risolto (es.: la sintassi è corretta, il campo esiste, ecc.)- In caso di successo,
@resolveValueAndMergechiama quindi il resolver del campo per risolvere il campo e unisce il valore nell'oggetto di risposta
Queste due direttive sono del tipo speciale "sistema": sono riservate esclusivamente al motore GraphQL e sono implicite su ogni campo. (Al contrario, le direttive standard sono esplicite: vengono aggiunte alla query dall'utente.)
Utilizzando queste due direttive, questa query:
query {
field1
field2 @directiveA
}...verrà risolta come questa:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge @directiveA
}Il pipeline ora si presenta così (nota che il pipeline riceve il campo come input, e non il suo valore risolto iniziale):

Slot del pipeline
Le direttive vengono normalmente eseguite dopo @resolveValueAndMerge, poiché il più delle volte comportano l'aggiornamento del valore del campo risolto. Tuttavia, esistono altre direttive che devono essere eseguite prima di @validate, oppure tra @validate e @resolveValueAndMerge.
Per esempio:
- Per misurare il tempo impiegato a risolvere un campo, la direttiva
@traceExecutionTimepuò ottenere l'ora corrente prima e dopo la risoluzione del campo, collocando le sotto-direttive@startTracingExecutionTimeall'inizio e@endTracingExecutionTimealla fine del pipeline - Una direttiva
@cachedeve verificare se un campo richiesto è in cache e restituire direttamente questa risposta, prima di eseguire@resolveValueAndMerge
Il pipeline offrirà quindi cinque slot diversi tramite la classe PipelinePositions, e la direttiva indicherà in quale di essi deve essere eseguita:
- Lo slot
"beginning": proprio all'inizio - Lo slot
"before-validate": prima che avvenga la validazione - Lo slot
"middle": dopo la validazione e prima della risoluzione del campo - Lo slot
"after-resolve": dopo la risoluzione del campo - Lo slot
"end": proprio alla fine
Il pipeline di direttive ora si presenta così (considerando solo 3 fasi, per semplificare):

Nota come le direttive @skip e @include possano essere soddisfatte così facilmente con questa architettura: collocate nello slot "middle", possono informare la direttiva @resolveValueAndMerge (insieme a tutte le direttive nelle fasi successive del pipeline) di non eseguirsi impostando il flag skipExecution su true.
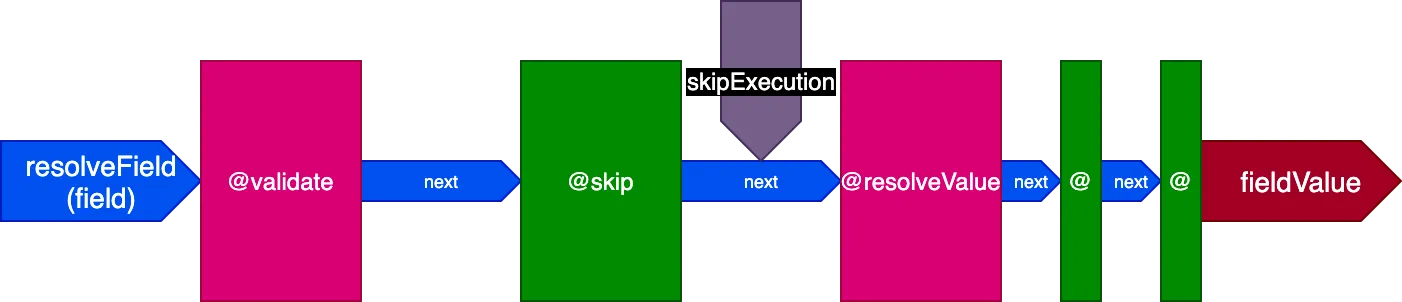
Eseguire la direttiva su più campi in una singola chiamata
Finora abbiamo considerato un singolo campo come input del pipeline di direttive. Tuttavia, in una tipica query GraphQL riceveremo diversi campi su cui eseguire le direttive.
Per esempio, nella query qui sotto, la direttiva @upperCase viene eseguita sui campi "field1" e "field2":
query {
field1 @upperCase
field2 @upperCase
field3
}Inoltre, poiché il motore GraphQL aggiunge le direttive di sistema @validate e @resolveValueAndMerge a ogni campo della query, in modo che questa query:
query {
field1
field2
field3
}...venga risolta come questa query:
query {
field1 @validate @resolveValueAndMerge
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}Allora, le direttive di sistema riceveranno sempre tutti i campi come input.
Di conseguenza, il pipeline di direttive è progettato per ricevere più campi come input, e non solo uno alla volta:

Questa architettura è più efficiente, perché eseguire una direttiva una sola volta per tutti i campi è più veloce che eseguirla una volta per campo, e produrrà gli stessi risultati.
Per esempio, durante la validazione del fatto che l'utente sia connesso per concedergli l'accesso allo schema, l'operazione può essere eseguita una sola volta. Eseguire il codice seguente:
if (isUserLoggedIn()) {
resolveFields([$field1, $field2, $field3]);
}è più efficiente che eseguire questo codice:
if (isUserLoggedIn()) {
resolveField($field1);
}
if (isUserLoggedIn()) {
resolveField($field2);
}
if (isUserLoggedIn()) {
resolveField($field3);
}Questo può non sembrare un grosso problema quando si chiama una funzione locale come isUserLoggedIn, tuttavia può fare una grande differenza quando si interagisce con servizi esterni, come nella risoluzione di endpoint REST tramite GraphQL. In questi casi, eseguire una funzione una sola volta invece di più volte potrebbe fare la differenza tra poter fornire o meno una determinata funzionalità.
Vediamo un esempio. Quando si interagisce con Google Translate tramite una direttiva @translate, l'API GraphQL deve stabilire una connessione sulla rete. Eseguire questo codice sarà il più veloce possibile:
googleTranslateFields([$field1, $field2, $field3]);Al contrario, eseguire la funzione separatamente, più volte, produrrà una latenza più elevata che si tradurrà in un tempo di risposta più lungo, degradando le prestazioni dell'API. Forse non è una grande differenza per tradurre 3 stringhe (dove il campo è la stringa da tradurre), ma per 100 o più stringhe avrà sicuramente un impatto:
googleTranslateField($field1);
googleTranslateField($field2);
googleTranslateField($field3);Inoltre, eseguire una funzione una sola volta con tutti gli input può produrre una risposta migliore rispetto a eseguire la funzione su ogni campo indipendentemente. Riprendendo come esempio Google Translate, la traduzione sarà più precisa quanti più dati forniamo al servizio.
Per esempio, eseguendo il codice qui sotto:
googleTranslate("fork");
googleTranslate("road");
googleTranslate("sign");Per la prima esecuzione indipendente, Google non conosce il contesto di "fork", quindi potrebbe benissimo rispondere con fork come utensile per mangiare, come una biforcazione di una strada, o con un altro significato. Tuttavia, se invece eseguiamo:
googleTranslate(["fork", "road", "sign"]);Da questa maggiore quantità di informazioni, Google può dedurre che "fork" si riferisce alla biforcazione della strada, e restituire una traduzione precisa.
È per queste ragioni che le direttive nel pipeline ricevono i campi di input tutti insieme, e ogni direttiva può quindi decidere il modo migliore per eseguire la propria logica su questi input (una singola esecuzione per input, una singola esecuzione comprendente tutti gli input, o qualsiasi via di mezzo).
Il pipeline ora si presenta così:
Eseguire un singolo pipeline di direttive per l'intera query
Abbiamo appena visto che ha senso eseguire più campi per direttiva, tuttavia questo funziona bene finché tutti i campi hanno le stesse direttive applicate. Quando le direttive sono diverse, ciò può portare a una maggiore complessità che ne rende difficile l'implementazione e ridurrebbe alcuni dei benefici ottenuti.
Vediamo come avviene tutto questo. Consideriamo la seguente query:
query {
field1 @directiveA
field2
field3
}Questa direttiva è equivalente a questa:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge
field3 @validate @resolveValueAndMerge
}In questo scenario, i campi field2 e field3 hanno lo stesso insieme di direttive, mentre field1 ne ha uno diverso; dovremmo quindi generare 2 pipeline diversi per risolvere la query:
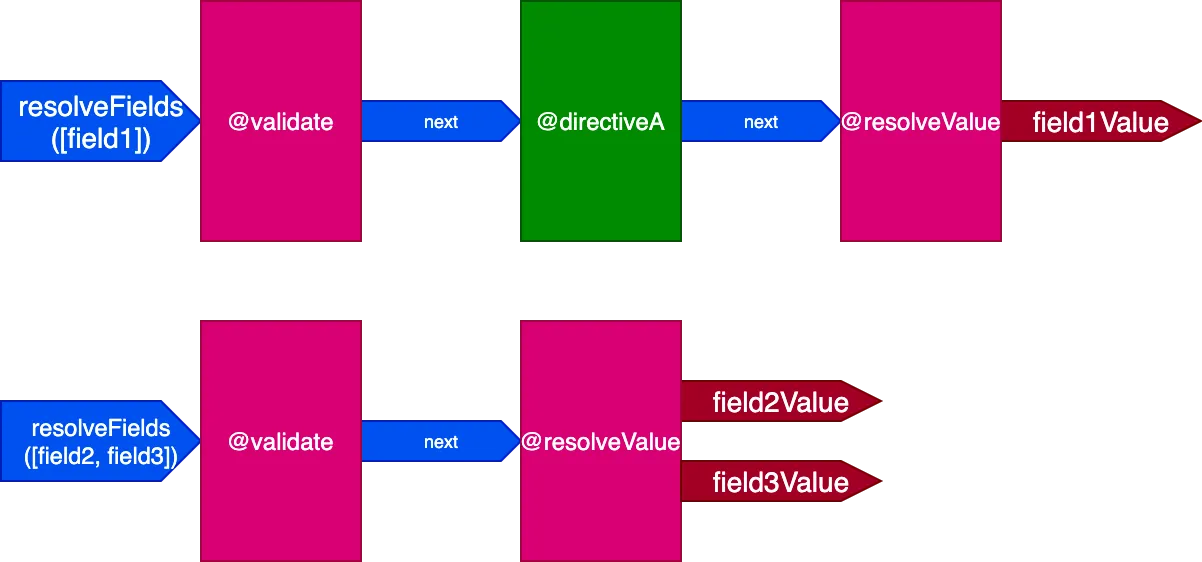
E quando tutti i campi hanno un insieme unico di direttive, l'effetto è ancora più marcato. Consideriamo questa query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}Che è equivalente a questa:
query {
field1 @validate @resolveValueAndMerge @directiveA
field2 @validate @resolveValueAndMerge @directiveB @directiveC
field3 @validate @resolveValueAndMerge @directiveC
}In questa situazione, avremo 3 pipeline per gestire 3 campi, in questo modo:
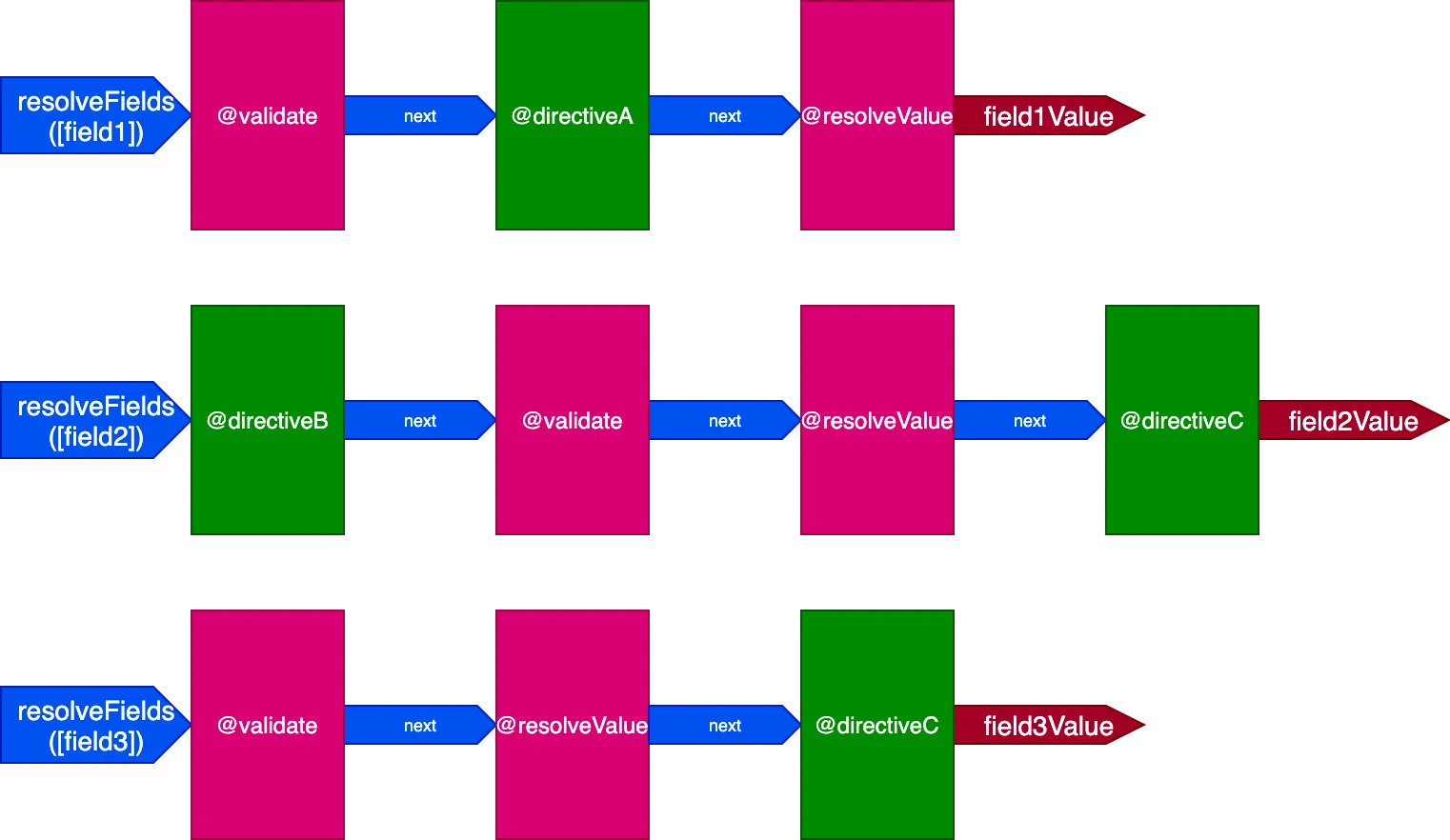
In questo caso, anche se le direttive @validate e @resolveValueAndMerge vengono applicate ai 3 campi, poiché vengono eseguite tramite 3 pipeline di direttive diversi, verranno eseguite indipendentemente l'una dall'altra, il che ci riporta ad avere una direttiva eseguita su un singolo elemento alla volta.
La soluzione a questo problema è evitare di produrre più pipeline, lavorando invece con un singolo pipeline per tutti i campi. Di conseguenza, il motore non passa più i campi come input al pipeline, poiché non tutte le direttive di un singolo pipeline interagiranno con lo stesso insieme di campi; al contrario, ogni direttiva deve ricevere la propria lista di campi come proprio input.
Allora, per questa query:
query {
field1 @directiveA
field2
field3
}...le direttive @validate e @resolveValueAndMerge riceveranno tutti e 3 i campi come input, e directiveA riceverà solo "field1":
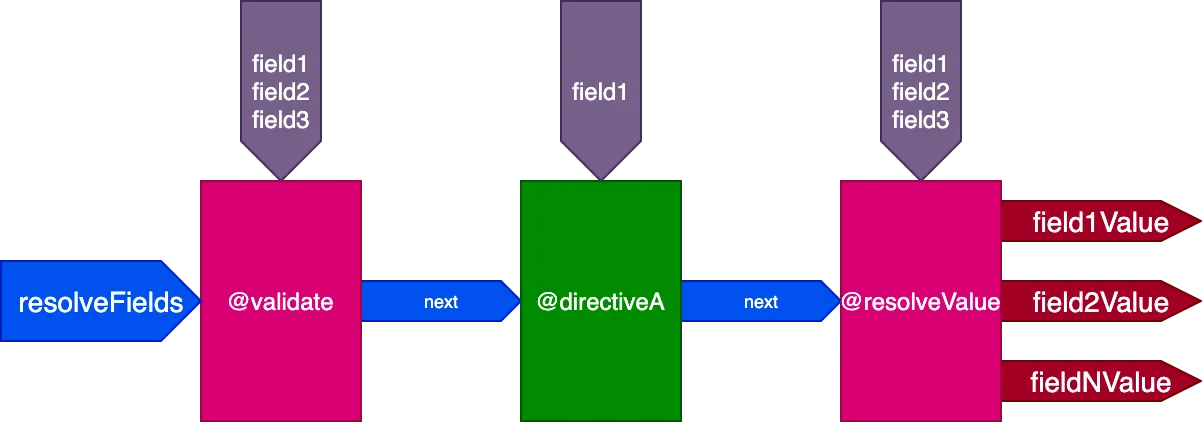
E per questa query:
query {
field1 @directiveA
field2 @directiveB @directiveC
field3 @directiveC
}...le direttive @validate e @resolveValueAndMerge riceveranno tutti e 3 i campi come input, directiveA riceverà solo "field1", directiveB riceverà solo "field2", e directiveC riceverà "field2" e "field3":
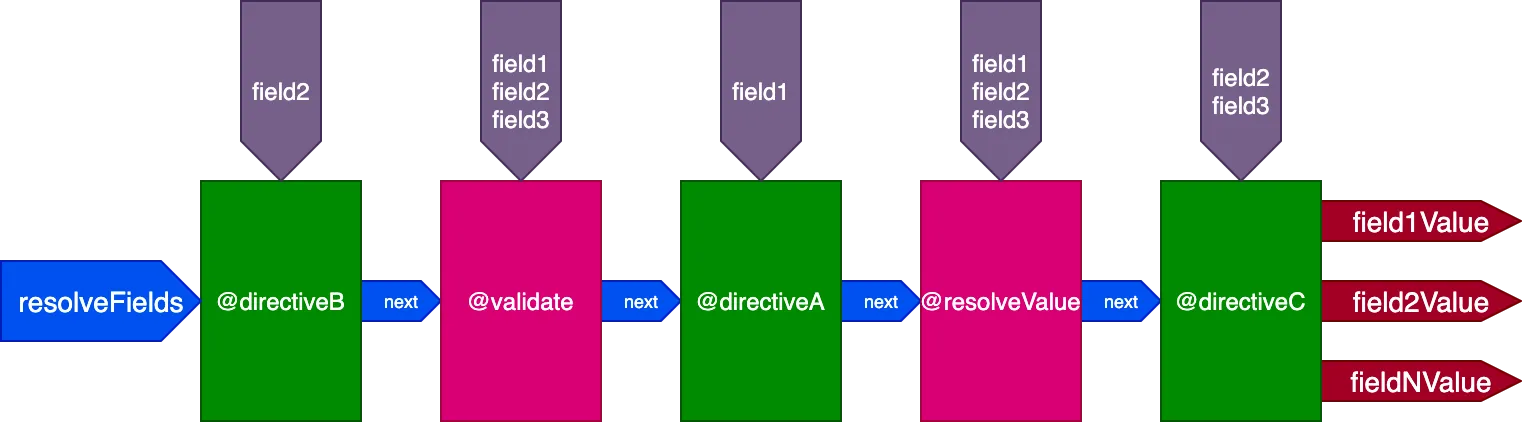
Controllare l'esecuzione della direttiva identificatore per identificatore
Finora, una direttiva in una certa fase poteva influenzare l'esecuzione delle direttive nelle fasi successive tramite un flag skipExecution. Tuttavia, questo flag non è sufficientemente granulare per tutti i casi.
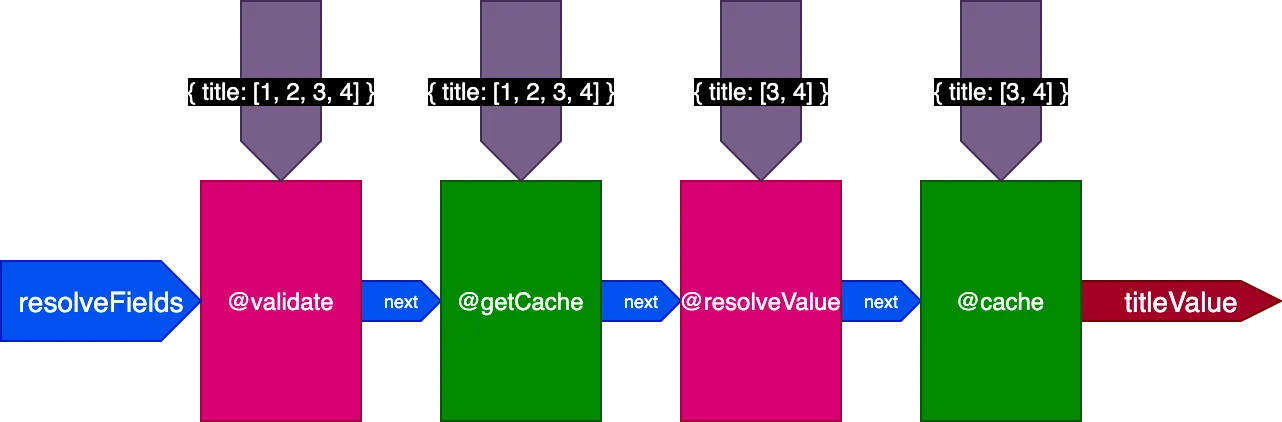
Per esempio, consideriamo una direttiva @cache, collocata nello slot "end" per memorizzare il valore del campo, in modo che la prossima volta che il campo viene interrogato, il suo valore possa essere recuperato dalla cache tramite una direttiva @getCache collocata nello slot "middle":
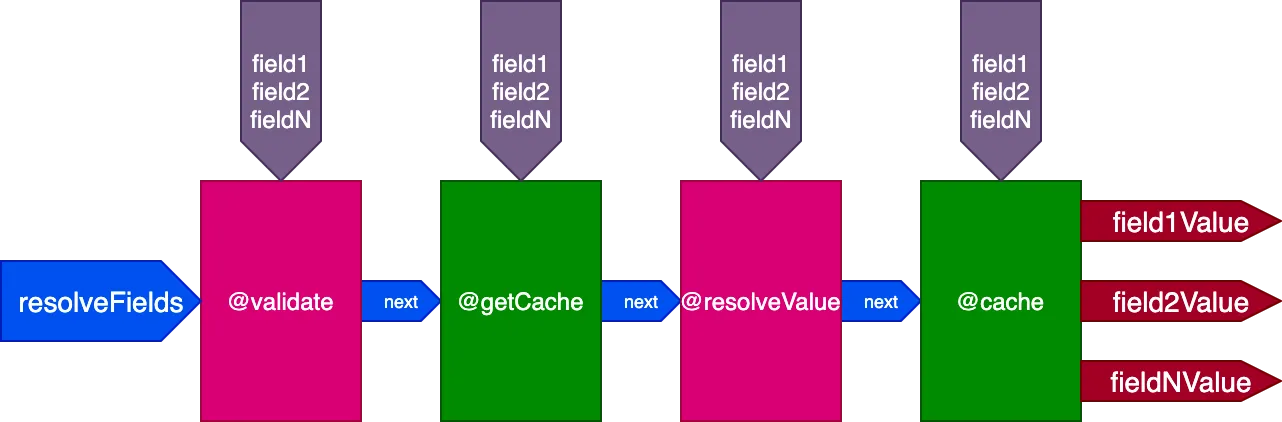
Durante l'esecuzione di questa query:
{
posts(pagination: { limit: 2 }) {
title @translate @cache
}
}Il server recupererà e metterà in cache 2 record. Quindi, eseguiamo la stessa query, ma applicata a 4 record:
{
posts(pagination: { limit: 4 }) {
title @translate @cache
}
}Durante l'esecuzione di questa 2ª query, i 2 record della 1ª query erano già in cache, ma gli altri 2 non lo erano. Tuttavia, avremmo bisogno che tutti e 4 i record fossero già in cache per poter utilizzare il flag skipExecution. Sarebbe meglio poter recuperare i primi 2 record dalla cache e risolvere solo gli altri 2 record.
Aggiorniamo quindi nuovamente il design del pipeline. Abbandoniamo il flag skipExecution e, al suo posto, passiamo a ogni direttiva la lista degli ID degli oggetti per campo su cui la direttiva deve essere applicata, tramite un oggetto di input fieldIDs:
{
field1: [ID11, ID12, ...],
field2: [ID21, ID22, ...],
...
fieldN: [IDN1, IDN2, ...],
}La variabile fieldIDs è unica per ogni direttiva, e ogni direttiva può modificare l'istanza di fieldIDs per tutte le direttive nelle fasi successive. Così, skipExecution può essere effettuato in modo granulare, ID per ID, semplicemente rimuovendo l'ID da fieldIDs per tutte le direttive successive nello stack.
Il pipeline ora si presenta così:
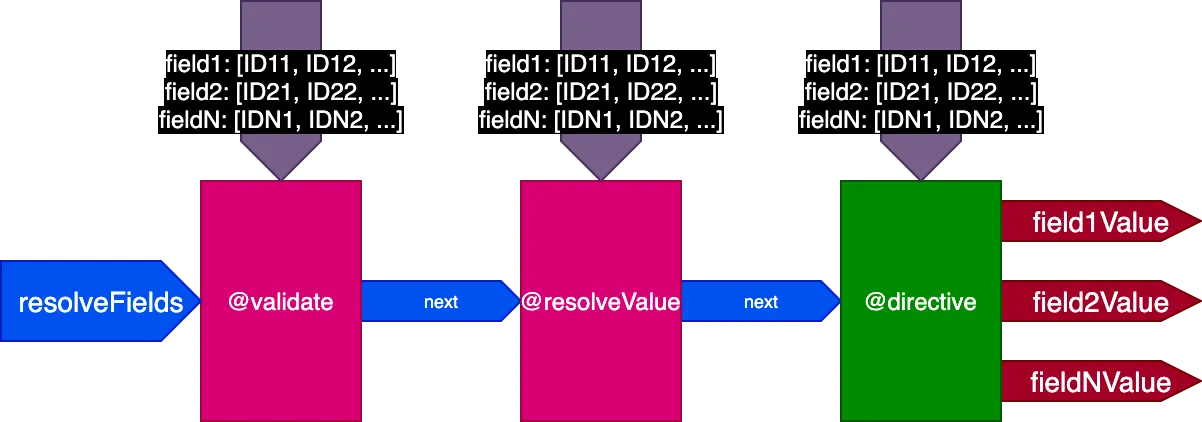
Applicato all'esempio precedente, durante l'esecuzione della prima query traducendo 2 record, il pipeline si presenta così:
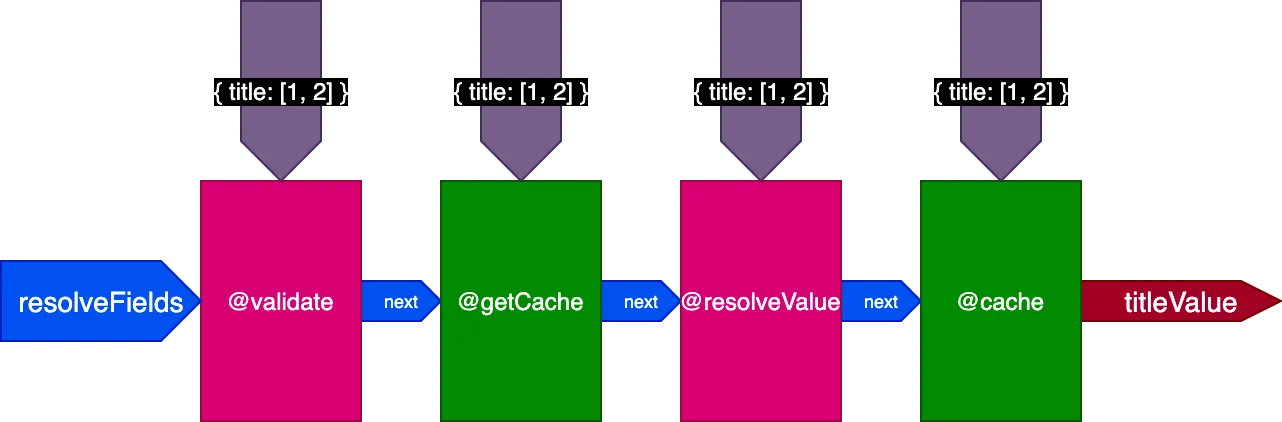
Durante l'esecuzione della seconda query traducendo 4 record, la direttiva @getCache riceve gli ID di tutti e 4 i record, ma sia @resolveValueAndMerge che @cache riceveranno solo gli ID degli ultimi 2 record (che non sono in cache):
Mettere tutto insieme
Ecco il design finale del pipeline di direttive:
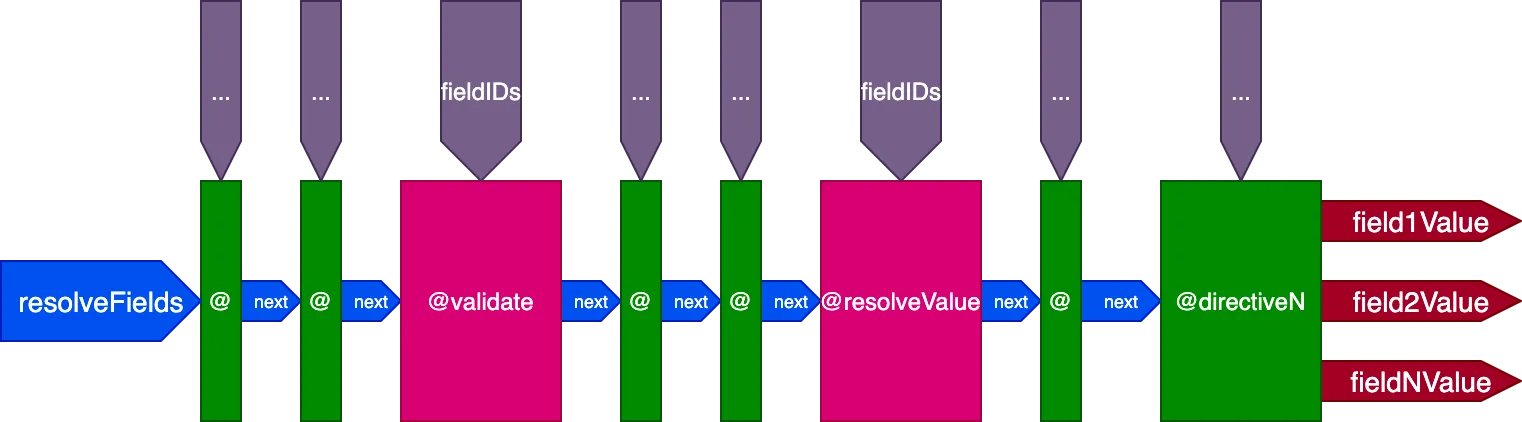
In sintesi, queste sono le sue caratteristiche:
- I resolver dei campi vengono invocati dall'interno del pipeline di direttive stesso, tramite le direttive
@validatee@resolveValueAndMerge - Le direttive possono essere collocate in uno dei 5 slot:
"beginning","before-validate","middle","after-validate"ed"end" - Le direttive risolvono più campi in una singola chiamata
- Un singolo pipeline contiene tutte le direttive coinvolte nella query
- Ogni direttiva riceve il proprio insieme di ID da risolvere per campo tramite la variabile
fieldIDs - Le direttive possono modificare la variabile
fieldIDsper tutte le direttive in una fase successiva del pipeline