
Manipolare l'ordine di risoluzione dei campi
L'obiettivo della direttiva @export fornita da Multiple Query Execution è esportare il valore di un campo (o di un insieme di campi) in una variabile, da utilizzare altrove nella query.
Questa direttiva non funzionerebbe se la lettura della variabile avvenisse prima dell'esportazione del valore nella variabile stessa. Pertanto, il motore deve fornire un modo per controllare l'ordine di esecuzione dei campi.
Gato GraphQL offre un modo per manipolare l'ordine di esecuzione dei campi attraverso la query stessa. Il motore carica i dati in iterazioni per ogni tipo, risolvendo prima tutti i campi del primo tipo che incontra nella query, poi tutti i campi del secondo tipo che incontra nella query, e così via fino a quando non ci sono più tipi da elaborare.
Ad esempio, la seguente query che coinvolge oggetti di tipo Director, Film e Actor:
{
directors {
name
films {
title
actors {
name
}
}
}
}...viene risolta dal motore GraphQL in questo ordine:

Se, dopo essere stato elaborato, un tipo viene nuovamente referenziato nella query per recuperare dati non caricati (ad esempio: da oggetti aggiuntivi, o campi aggiuntivi di oggetti già caricati), allora il tipo viene aggiunto di nuovo alla fine della lista di iterazione.
Ad esempio, se interroghiamo anche il campo preferredDirector dell'Actor (che restituisce un oggetto di tipo Director) in questo modo:
{
directors {
name
films {
title
actors {
name
preferredDirector {
name
}
}
}
}
}...allora il motore GraphQL elabora la query in questo ordine:

Vediamo come ciò si svolge per l'esecuzione di @export in una singola query. Per il nostro primo tentativo, creiamo la query come faremmo normalmente, senza pensare all'ordine di esecuzione dei campi:
query GetPostsAuthorNames {
user(by: { id: 1 }) {
name @export(as: "authorName")
}
posts(filter: { search: $authorName }) {
id
title
}
}Durante l'esecuzione, la query produce questa risposta:
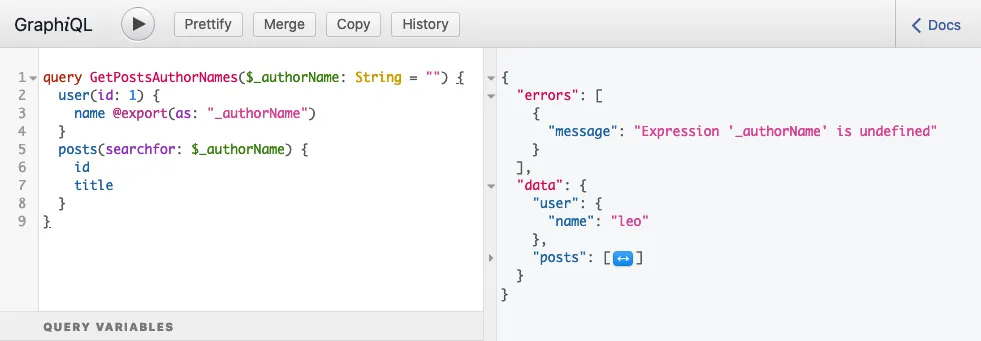
...che contiene il seguente errore:
{
"errors": [
{
"message": "Expression 'authorName' is undefined",
}
]
}Questo errore significa che, nel momento in cui la variabile $authorName è stata letta, non era ancora stata impostata; era undefined.
Vediamo perché ciò accade. Innanzitutto, analizziamo quali tipi appaiono nella query, aggiunti come commenti qui sotto:
# Type: Root
query GetPostsAuthorNames {
# Type: User
user(by: {id: 1}) {
# Type: String
name @export(as: "authorName")
}
# Type: Post
posts(filter: { search: $authorName }) {
# Type: ID
id
# Type: String
title
}
}Per elaborare i tipi e caricare i loro dati, il motore di caricamento dei dati aggiunge il tipo della query Root in una lista FIFO (First-In, First-Out, "primo entrato, primo uscito"), rendendo così [Root] la lista iniziale passata all'algoritmo, e quindi itera sui tipi in modo sequenziale, come segue:
| # | Operazione | Lista |
|---|---|---|
| 0 | Preparare la lista FIFO | [Root] |
| 1a | Estrarre il primo tipo della lista (Root) | [] |
| 1b | Elaborare tutti i campi interrogati del tipo Root:→ user(by: {id: 1})→ posts(filter: { search: $authorName })Aggiungere i loro tipi ( User e Post) alla lista | [User, Post] |
| 2a | Estrarre il primo tipo della lista (User) | [Post] |
| 2b | Elaborare il campo interrogato del tipo User:→ name @export(as: "authorName")Poiché è un tipo scalare ( String), non è necessario aggiungerlo alla lista | [Post] |
| 3a | Estrarre il primo tipo della lista (Post) | [] |
| 3b | Elaborare tutti i campi interrogati del tipo Post:→ id→ titlePoiché sono tipi scalari ( ID e String), non è necessario aggiungerli alla lista | [] |
| 4 | La lista è vuota, l'iterazione termina. |
Qui possiamo vedere il problema: @export viene eseguito al passo 2b, ma è stato letto al passo 1b.
È qui che dobbiamo controllare il flusso di esecuzione dei campi. La soluzione implementata consiste nel ritardare il momento in cui la variabile esportata viene letta, ottenuto interrogando artificialmente il campo self del tipo Root.
Il campo self, come indica il nome, restituisce lo stesso oggetto; applicato all'oggetto Root, restituisce lo stesso oggetto Root. Potresti chiederti: "se ho già l'oggetto radice, perché dovrei recuperarlo di nuovo?". Perché allora l'algoritmo del motore dovrà aggiungere questo nuovo riferimento a Root alla fine della lista FIFO, e possiamo deliberatamente distribuire i campi interrogati prima o dopo ciascuna di queste iterazioni.
Ecco perché il campo posts(filter:{ search: $authorName }) è posto all'interno di un campo self nella query qui sopra, e l'esecuzione della query produce la risposta attesa:
query GetPostsAuthorNames {
user(by: {id: 1}) {
name @export(as: "authorName")
}
self {
posts(filter: { search: $authorName }) {
id
title
}
}
}
Esploriamo l'ordine in cui i tipi vengono elaborati per questa query, per capire perché funziona correttamente:
| # | Operazione | Lista |
|---|---|---|
| 0 | Preparare la lista FIFO | [Root] |
| 1a | Estrarre il primo tipo della lista (Root) | [] |
| 1b | Elaborare tutti i campi interrogati del tipo Root:→ user(by: {id: 1})→ selfAggiungere i loro tipi ( User e Root) alla lista | [User, Root] |
| 2a | Estrarre il primo tipo della lista (User) | [Root] |
| 2b | Elaborare il campo interrogato del tipo User:→ name @export(as: "authorName")Poiché è un tipo scalare ( String), non è necessario aggiungerlo alla lista | [Root] |
| 3a | Estrarre il primo tipo della lista (Root) | [] |
| 3b | Elaborare il campo interrogato del tipo Root:→ posts(filter:{ search: $authorName })Aggiungere il suo tipo ( Post) alla lista | [Post] |
| 4a | Estrarre il primo tipo della lista (Post) | [] |
| 4b | Elaborare tutti i campi interrogati del tipo Post:→ id→ titlePoiché sono tipi scalari ( ID e String), non è necessario aggiungerli alla lista | [] |
| 5 | La lista è vuota, l'iterazione termina. |
Ora possiamo vedere che il problema è stato risolto: @export viene eseguito al passo 2b, e viene letto al passo 3b.
Multiple Query Execution fa esattamente questo durante il disaccoppiamento delle query: converte il documento GraphQL aggiungendo campi self, affinché i campi di ogni operazione vengano eseguiti solo dopo che tutti i campi di tutte le operazioni precedenti sono stati risolti.